

A Note on Regular Expressions
They’re a bitch 🙂
It seems I was waaay too quick in my bugfixes article. In it I state that
elsif m = /(.*)("[^\\"]*")(.*)/.match(txt)would solve the “Some escaped \”quotes\” in a string problem”. Of course it doesn’t. Given the following line:
((sym? L) (link (pack "\"" (esc> '+Str L '("\"")) "\"")))It will match (in curly brackets): {((sym? L) (link (pack “\”” (esc> ‘+Str L ‘(“\””)) “\} {“”} {)))}. Hardly what we want.
My first impulse was to consider the middle sub-expression (“[^\\”]*”). I wanted to include all types of characters but a double quote, unless that quote didn’t have a backslash in front of it, in which case it should be ignored. However the answer doesn’t lie within the [^\\”] character set, but outside of it:
/(.*)([^\\]".*[^\\]")(.*)/.match(txt)The above almost fixed the problem, let’s look at the matching pattern of ‘(“\””) to understand why it almost but not quite got me there: {‘} {(“\””} {)}.
Oops, that left parenthesis just got highlighted as a string and since the bracket highlighting is dependent on the style type this will screw it up. A screwed bracket matching situation translates directly into a screwed working situation when coding Lisp. We really need to fix this.
/(.*)([^\\])(".*[^\\]")(.*)/.match(txt)The above will solve the situation, we get this pattern: {‘} {(} {“\””} {)}. Finally what we want, bad news is that four results will need their own handling since the styleLine in Pico only handles three results. The whole styleMe method now looks like this:
def styleMe(txt, sci, flag = :def)
if txt && txt.length > 0
if (m = /(.*)(#.*)/.match(txt)) && (flag != :nocmt)
a, b = m.captures
if a.length > 0 && a.scan('"').length % 2 != 0
self.styleMe(txt, sci, :nocmt)
else
self.styleMe(a, sci)
sci.set_styling(b.length, STC_LISP_COMMENT)
end
elsif m = /(.*)([^\\]"")(.*)/.match(txt)
self.styleLine(m, sci, STC_LISP_STRING)
elsif m = /(.*)([^\\])(".*[^\\]")(.*)/.match(txt)
a, b, c, d = m.captures
self.styleMe(a, sci)
self.styleTxt(b, sci)
sci.set_styling(c.length, STC_LISP_STRING)
self.styleMe(d, sci)
elsif m = /(.*)('[^()\s]+)(.*)/.match(txt)
self.styleLine(m, sci, STC_LISP_SYMBOL)
elsif m = /(.*)([()\s])(.*)/.match(txt)
if m.captures[1] != ' '
self.styleLine(m, sci, STC_LISP_OPERATOR)
else
self.styleLine(m, sci, STC_LISP_DEFAULT)
end
else
if @project.getConfig(@proj_id, :pico).fetch(:all_keywords).include?(txt.strip)
sci.set_styling(txt.length, STC_LISP_KEYWORD)
else
self.styleTxt(txt, sci)
end
end
end
endThe styleTxt method is new:
def styleTxt(txt, sci)
if txt.strip =~ /^\d+$/
sci.set_styling(txt.length, STC_LISP_NUMBER)
elsif "'*/-+();~,.`".include?(txt.strip)
sci.set_styling(txt.length, STC_LISP_OPERATOR)
else
sci.set_styling(txt.length, STC_LISP_DEFAULT)
end
endThe left parenthesis above will get caught by the include? check and hence get the needed STC_LISP_OPERATOR style. The statement just above where all this begins in styleMe: elsif m = /(.*)([^\\]””)(.*)/.match(txt) will take care of the empty string edge case: “”, and will also correctly handle “\””.
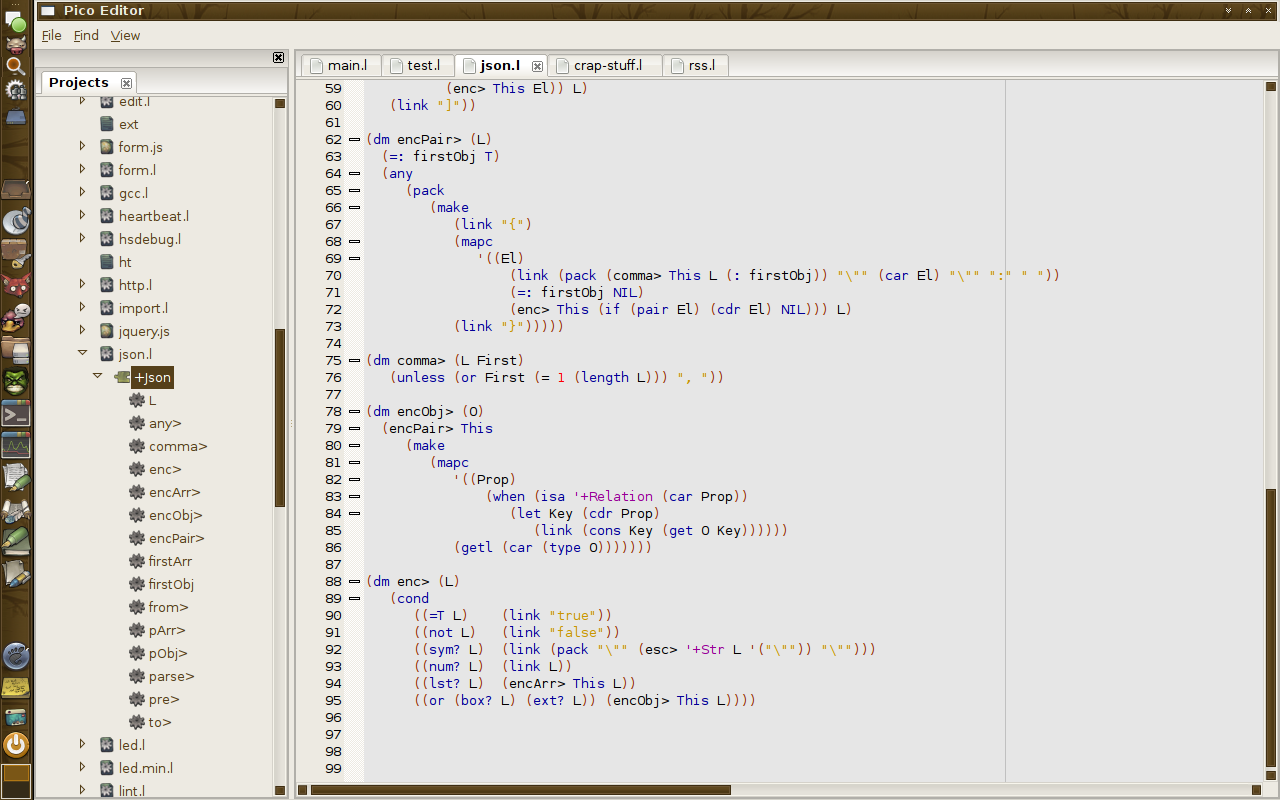
Finally, hopefully, all is well! 🙂
Update Oct 2008: In turned out that all solutions except Piers‘ below in the comments lead to madness in the end, the styling method now looks like this and is managing all cases.
def styleMe(txt, sci, flag = :def)
if txt && txt.length > 0
if (m = /(.*)(#.*)/.match(txt)) && (flag != :nocmt)
a, b = m.captures
if a.length > 0 && a.scan('"').length % 2 != 0
self.styleMe(txt, sci, :nocmt)
else
self.styleMe(a, sci)
sci.set_styling(b.length, STC_LISP_COMMENT)
end
elsif m = /([^"]*)("[^\\"]*(?:\\.[^\\"]*)*")(.*)/.match(txt)
self.styleLine(m, sci, STC_LISP_STRING)
elsif m = /(.*)('[^()\s]+)(.*)/.match(txt)
self.styleLine(m, sci, STC_LISP_SYMBOL)
elsif m = /(.*)([()\s])(.*)/.match(txt)
if m.captures[1] != ' '
self.styleLine(m, sci, STC_LISP_OPERATOR)
else
self.styleLine(m, sci, STC_LISP_DEFAULT)
end
else
if @project.getConfig(@proj_id, :pico).fetch(:all_keywords).include?(txt.strip)
sci.set_styling(txt.length, STC_LISP_KEYWORD)
else
self.styleTxt(txt, sci)
end
end
end
endIf you look carefully you will see that Piers made himself guilty of a typo, it’s fixed in the code above though.
The editor source has been updated.
Related Posts
Tags: regular expressions, Ruby, wxruby